
広告の「学習」って何してるの? 仕組みがわかるとコンバージョン設定の意味が変わる
「学習中です」の裏で何が起きているのか。コンバージョン設定が正解データである理由を、天気予報の予測コードとGoogle公式資料から解説する
コラム
kkm
Backend Engineer / AWS / Django
広告の「学習中」って、何をしてるのか

Google広告の管理画面を開くと、入札戦略のステータスに「学習中」と表示されていることがあります。キャンペーンを新しく作ったとき、設定を大きく変えたとき。だいたい出てきます。
この「学習」、なんとなくのイメージで使っている人が多いんじゃないでしょうか。「AIが頑張ってくれている期間」くらいの認識で、あとは待つだけ。
実はこの「学習」、マーケティング用語ではなく技術用語としての機械学習(Machine Learning)そのものです。Googleは公式にこう書いています。
「スマート自動入札」とは、機械学習を使用して個々のオークションのコンバージョン数やコンバージョン値を最適化する入札戦略のことです。
「機械学習を使用して」。はっきり書いてあります。つまり、管理画面の「学習中」は比喩でもブランディングでもなく、文字通り機械学習アルゴリズムがデータを処理している最中ということです。
仕組みがわかると設定の意味が変わる
「機械学習だったんだ、へぇ」で終わってしまうと、この記事の意味がありません。大事なのはその先です。
機械学習の仕組みがわかると、広告運用で「なぜそうしなければならないのか」が見えてきます。たとえば、こういう疑問。
- ? なぜ学習期間中にキャンペーン設定を変えてはいけないのか
- ? なぜコンバージョンの定義をちゃんと設計する必要があるのか
- ? なぜコンバージョン数が少ないと「学習」がうまくいかないのか
これらは全部、機械学習の仕組みから説明がつきます。「そういうものだから」ではなく、「こういう計算をしているから」と理解できる。すると設定画面の一つ一つに根拠が持てるようになります。
この記事では、天気予報を予測するという身近な例を使って、機械学習が何をやっているのかを説明します。そのうえで、広告の「学習」との構造的な一致を見ていきます。
機械学習を体験してみる
ちょっとクイズです。ここ3日間の東京の最高気温を見てください。
| 最高気温 | |
|---|---|
| 3日前 | 22°C |
| 2日前 | 23°C |
| 昨日 | 21°C |
| 明日 | → 何度くらい? |
「22°Cくらいかな」と思いませんでしたか。3日連続で21〜23°Cなんだから、明日もそのあたりだろう、と。
おめでとうございます。今あなたがやったことが、機械学習の基本です。過去のデータからパターンを見つけて、未来を予測する。機械学習はこれをコンピュータが自動でやっているだけです。
ただし、この予測にはいくつか落とし穴があります。
データを増やしてみると
実はこの3日間は梅雨の真っ最中のデータでした。そして翌日は梅雨明け。最高気温は30°C。大外れです。3日分では季節の変わり目は見えませんでした。
では、もう少しさかのぼって7日分のデータを見てみましょう。
| 最高気温 | |
|---|---|
| 7日前 | 29°C |
| 6日前 | 27°C |
| 5日前 | 23°C |
| 4日前 | 22°C |
| 3日前 | 22°C |
| 2日前 | 23°C |
| 昨日 | 21°C |
| 明日 | → 何度くらい? |
7日分見ると、7日前と6日前は29°C、27°Cと暑い日がありました。21〜29°Cの幅がある。3日分だけ見たときの「22°C」よりは、「24〜25°Cくらいかな」と幅を持った予測ができそうです。データの量が増えると、見えるパターンが増えて、予測の精度が上がります。
でも、実際の30°Cにはまだ全然届きません。最高気温だけでは限界があります。
手がかりを増やしてみると
同じ7日間に、天気の列を足してみます。
| 最高気温 | 天気 | |
|---|---|---|
| 7日前 | 29°C | 晴れ |
| 6日前 | 27°C | 晴れ |
| 5日前 | 23°C | 雨 |
| 4日前 | 22°C | 雨 |
| 3日前 | 22°C | 雨 |
| 2日前 | 23°C | 雨 |
| 昨日 | 21°C | 雨 |
| 明日 | → ? | 晴れの予報 |
見えてきませんか。晴れの日は27〜29°C、雨の日は21〜23°C。きれいに分かれています。そして明日の天気予報は晴れ。
「28°Cくらいかな」。実際の30°Cにかなり近い予測ができました。
手がかりの種類が増えると、見つけられるパターンも増えて、予測の精度がさらに上がります。
今やったことが、機械学習です
ここまでの流れを振り返ると、あなたは3つのことをやりました。
- 1. 過去のデータ(気温、天気)を手がかりにして、翌日の気温を予測した
- 2. 実際の気温(正解)と比べて、予測がずれていることに気づいた
- 3. データの量や手がかりの種類を増やして、予測を改善した
機械学習は、これをコンピュータが何万件ものデータで自動的にやっているだけです。そしてこの構造が、広告の「学習」とそのまま重なります。
もう一問。コンビニのアイスで考える
同じ考え方が別の場面でも使えるか、試してみましょう。あなたはコンビニの店長で、今日のアイスの発注数を決めなければいけません。
| 売上 | |
|---|---|
| 2日前 | 120個 |
| 昨日 | 130個 |
| 今日 | → 何個くらい売れる? |
「130個くらいかな、増えてるし」。今日の売上は50個でした。大外れです。なぜでしょう。
データを増やしてみると
6日分にさかのぼってみましょう。
| 売上 | |
|---|---|
| 6日前 | 50個 |
| 5日前 | 45個 |
| 4日前 | 110個 |
| 3日前 | 55個 |
| 2日前 | 60個 |
| 昨日 | 120個 |
| 今日 | → 何個くらい? |
パターンが見えてきませんか。50、45、110、55、60、120。2日くらい低い日が続いた後に1日跳ねる。だとすると今日は低い日で、50個くらい?
今日の売上は130個でした。また外れです。「2日低い→1日高い」のサイクルだと思ったのに。
曜日の列を足すと
| 売上 | 曜日 | |
|---|---|---|
| 6日前 | 50個 | 月 |
| 5日前 | 45個 | 火 |
| 4日前 | 110個 | 水(祝日) |
| 3日前 | 55個 | 木 |
| 2日前 | 60個 | 金 |
| 昨日 | 120個 | 土 |
| 今日 | 130個 | 日 |
| 明日 | → ? | 月 |
「2日サイクル」ではありませんでした。土日祝は100個以上、平日は45〜60個。水曜の110個は祝日だったから。今日が130個だったのは日曜日だから。明日は月曜なので、50個くらいでしょう。
手がかりが足りないと、間違ったパターンを見つけてしまう。正しい手がかりがあれば、正しいパターンが見える。さらに天気やキャンペーン割引の有無を足せば、「平日でも猛暑なら70個売れる」「割引チラシを出した日は+20個」のようにもっと細かく予測できます。天気予測のときとまったく同じ構造です。
「何を正解にするか」でも結果が変わる
もう一つだけ。ここまで「アイスの売上」を正解にして予測してきましたが、もし正解を「来店した客数」に変えたらどうなるか。
| 天気 | アイス売上 | 来店客数 | |
|---|---|---|---|
| 猛暑の平日 | 晴れ 35°C | 70個 | 300人 |
| 雨の土曜 | 雨 22°C | 40個 | 450人 |
雨の土曜は、駅前のコンビニには傘を買いに人が来ます。来店客数は450人。でもアイスは40個しか売れません。
もし「来店客数」を正解にして発注を予測したら、「雨の土曜は人が来るから大量発注だ」となります。アイスは余ります。「何を正解にするか」を間違えると、予測の方向そのものがずれる。
「個数」で数えるか、「金額」で重みをつけるか
正解を「アイスの売上」にしたとして、もう一つ考えることがあります。(※ 以下の金額はわかりやすさのため丸めています)
| 商品 | 売れた数 | 売上金額 |
|---|---|---|
| ¥70のガリガリ君 | 100本 | ¥7,000 |
| ¥3,500のホールケーキアイス | 10個 | ¥35,000 |
「売れた個数」を正解にすると、ガリガリ君100本 vs ホールケーキ10個。機械学習は「ガリガリ君が売れるパターン」を10倍重視します。仕入れは安いアイス中心になる。
「売上金額」で重みをつけると、ガリガリ君¥7,000 vs ホールケーキ¥35,000。逆転して、ホールケーキのパターンの方が5倍重要になります。同じ「売上」を正解にしていても、個数で数えるか金額で重みをつけるかで、最適化の方向がまるで逆になる。これも後ほど、広告の話に直結します。
天気予報と広告の「学習」は同じ構造
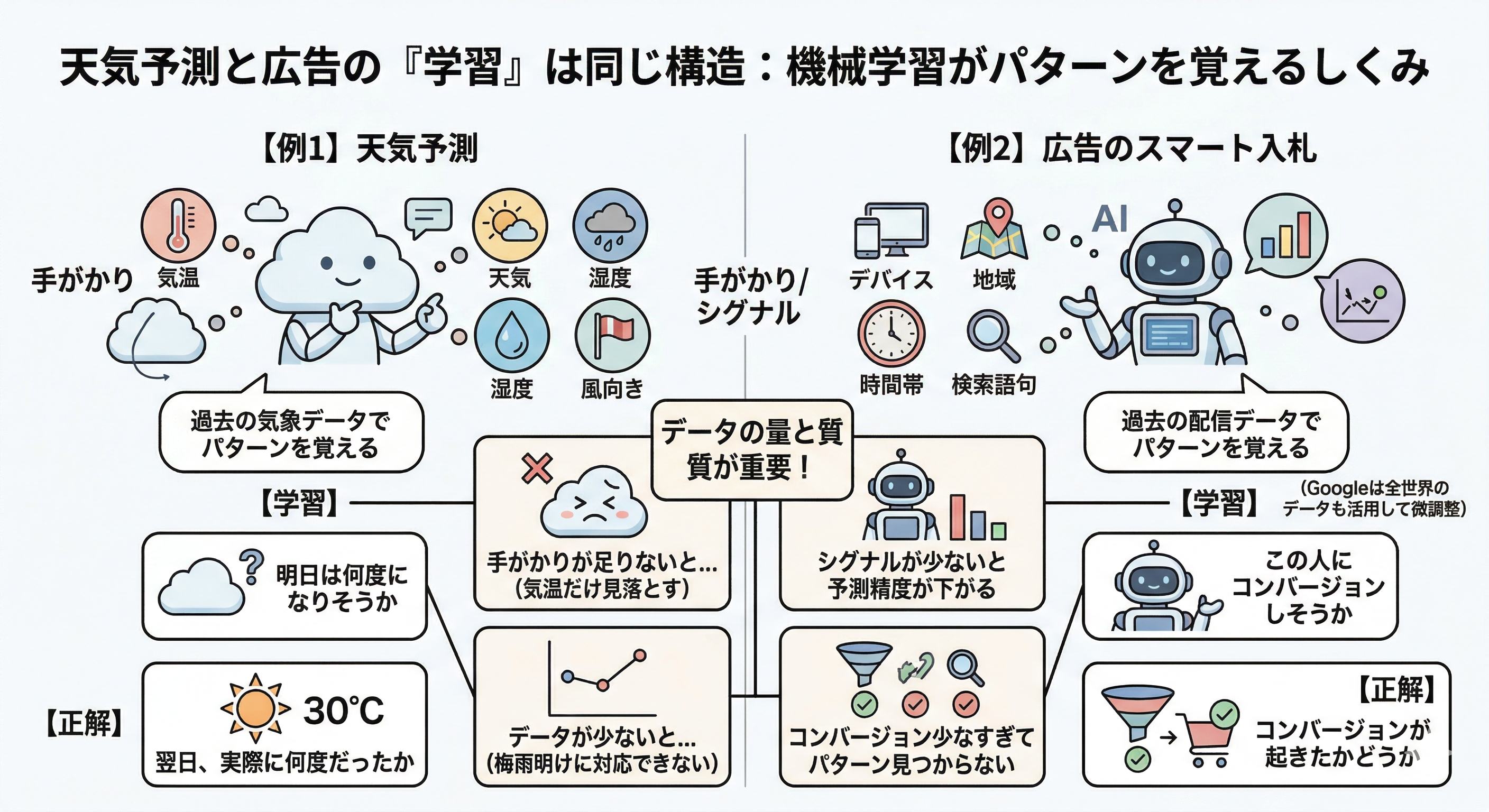
天気予測と広告のスマート入札を並べると、やっていることが同じだとわかります。
| 役割 | 天気予測 | 広告のスマート入札 |
|---|---|---|
| 予測の手がかり | 気温、天気、湿度、風向きなど | デバイス、地域、時間帯、検索語句など |
| 正解 | 翌日、実際に何度だったか | コンバージョンが起きたかどうか |
| 学習 | 過去の気象データでパターンを覚える | 過去の配信データでパターンを覚える |
| 予測 | 明日は何度になりそうか | この人に広告を出したらコンバージョンしそうか |
| 手がかりが足りないと | 気温だけ見て天気を見落とす | シグナルが少ないと予測精度が下がる |
| データが少ないと | 梅雨の3日分では梅雨明けに対応できない | コンバージョンが少なすぎてパターンが見つからない |
広告のスマート入札は、この天気予測を超高速でやっています。Google公式のホワイトペーパーによると、デバイス・地域・時間帯・OS・ブラウザ・言語・検索語句など多数の手がかり(Googleはこれを「シグナル」と呼んでいます)を、オークションのたびに1回1回評価しています。広告を表示するかどうかを決める段階で、毎回この評価が走っています。
天気予測で「気温しか見てなくて梅雨明けを見落とした」のと同じように、シグナルが不足すると広告の予測もずれます。
補足: Googleの機械学習は「あなたのデータだけ」で学習しているわけではない
この記事では「あなたのコンバージョンデータで学習する」というシンプルな説明をしていますが、実態はもう少し複雑です。Googleは全世界の広告主のデータを活用した大規模な予測モデルを持っていると考えられます。
実際、Google公式のホワイトペーパーでも、あるキーワードに十分なデータがなくても、アカウント内の他のキーワードや検索クエリのデータを活用して入札を最適化すると説明されています。
つまり「30件のコンバージョンでゼロから学習する」のではなく、「Googleが持つ膨大なデータで作られた予測モデルに、あなたのアカウントのデータで微調整をかける」のが実態に近い。ただし、Googleは内部のアルゴリズム構造を公開していないため、この点は公式情報からの推測です。
いずれにせよ、あなたのアカウントのコンバージョンデータが「正解」として学習に使われるという基本構造は変わりません。
そしてデータの量についても同じです。Googleはスマート入札の運用に必要なコンバージョン数の目安を示していて、入札戦略によって異なります。たとえば目標コンバージョン単価(Target CPA)では過去30日間に30件以上、目標広告費用対効果(Target ROAS)のような金額ベースの戦略ではさらに多くのデータが推奨されています。「3日分の天気データでは季節の変化に対応できない」のと同じ理由で、コンバージョンデータが少ないと機械学習はパターンを見つけられません。
コンバージョン設定は「正解データ」を教えること
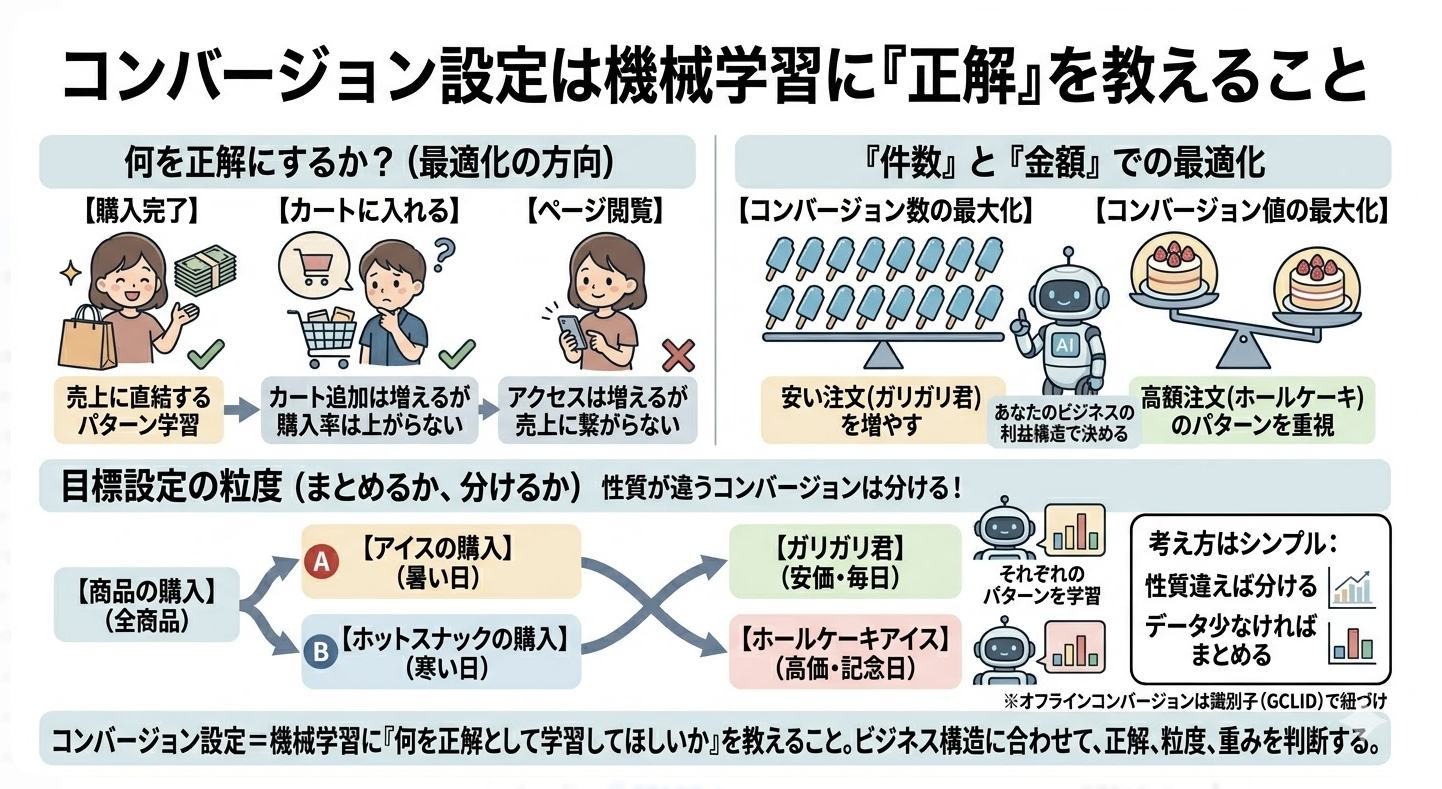
ここが一番大事なところです。
アイスの例で体験しましたね。「売上」を正解にすれば売上のパターンを学習するけれど、「来店客数」を正解にしたら、雨の土曜にアイスを大量発注する結果になる。何を正解にするかで、最適化の方向がまったく変わります。
広告の場合、この「正解」にあたるのがコンバージョン設定です。そして天気やアイスと違い、何を正解にするかは広告主が自分で決めます。ここを間違えると、機械学習は間違った方向に全力で最適化します。
| コンバージョンの設定 | 機械学習が覚えるパターン | 起きること |
|---|---|---|
| 購入完了 | 購入しやすいユーザーの特徴 | 売上に直結する最適化 |
| カートに入れる | 商品を見て回るユーザーの特徴 | カート追加は増えるが購入率は上がらない |
| ページ閲覧 | サイトを見るだけのユーザーの特徴 | アクセスは増えるが売上に繋がらない |
どのコンバージョンを設定しても、機械学習はそれを正解として忠実に学習します。「ページ閲覧」を正解にすれば、ページを見るだけのユーザーを集める天才になります。ただ、それはおそらくあなたが求めていた最適化ではない。
「件数」と「金額」でも最適化が変わる
アイスの例で「個数で数えるか、金額で重みをつけるか」を体験しました。広告でも同じ選択があります。
ガリガリ君とホールケーキの話を思い出してください。「コンバージョン数の最大化」は「個数で数える」のと同じです。¥1,000の注文も¥100,000の注文も同じ「1件」。機械学習はガリガリ君をたくさん買うような、安い注文を増やす方向に最適化します。
「コンバージョン値の最大化」は「金額で重みをつける」のと同じです。¥100,000の注文は¥1,000の100倍重い正解。機械学習はホールケーキを買うような、高額注文のパターンを重視して学習するようになります。
じゃあ「値の最大化」が最強かというと、そうでもありません。月額¥980の定額サービスのように、どの申し込みもほぼ同じ金額なら、金額で重みをつける意味がない。件数を増やす方が合理的です。コンビニで言えば、ガリガリ君を1本でも多く売ることが利益に直結するなら、個数で最適化する方が正しい。どちらが正解かは、あなたのビジネスが何で利益を出しているかで決まります。
雑な設定が学習を迷わせる
もう一つありがちなケースがあります。コンバージョン設定をアカウント作成時のデフォルトのまま放置しているパターンです。
たとえば、営業向けの問い合わせフォームとメルマガ登録フォームを同じコンバージョンとしてカウントしていたらどうなるか。機械学習から見ると、「営業問い合わせ=1件の正解」と「メルマガ登録=1件の正解」が同じ重みです。
アイスの例に戻すなら、「アイスが1個売れた」と「お客さんが店内を30秒見て帰った」を同じ「正解」として学習させているようなものです。何を最適化しているのか、機械学習にもわかりません。
コンバージョン目標は分けるべきか、まとめるべきか
もう一つ、実務でよくある悩みがあります。複数の種類のコンバージョンを、1つの目標にまとめるか、別々に分けるか。
たとえばアイスの話で言えば、同じコンビニで「アイス」と「ホットスナック」を売っているとします。これを「全商品の売上」として1つにまとめたらどうなるか。アイスは猛暑日に売れて、ホットスナックは寒い日に売れる。真逆のパターンです。まとめて学習させると、機械学習はどちらのパターンを覚えればいいのかわからなくなります。
コンビニの例で言えば、分け方にはいろいろな「深さ」があります。
- ざっくり: 「商品の購入」(全部まとめて1目標)
- ↓ 分ける: 「アイスの購入」「ホットスナックの購入」(カテゴリ別)
- ↓ もっと分ける: 「ガリガリ君」「ホールケーキアイス」(商品別)
ホットスナックを買いたい人とアイスを買いたい人では、来店する天気も時間帯も違うはずです。さらに細かく見れば、ガリガリ君を買う層とホールケーキを買う層でも年齢層や好みが違うかもしれない。分けるほど、それぞれのパターンをピンポイントで学習できます。
しかも分け方は「商品カテゴリ」だけではありません。「¥500以上の商品」と「¥500以下の商品」という金額の軸で分けることもできる。どの軸で、どこまで細かく分けるかは、ビジネスの構造によります。
広告でもまったく同じです。性質が違うコンバージョンを1つの目標にまとめると、機械学習が学習するパターンがぼやけます。ユーザー層も行動も違うものを同じ「正解」として渡している状態です。
ただし、分ければいいという話でもありません。天気予測のセクションで体験したように、データが少ないとパターンが見つからない。コンバージョンを細かく分けすぎて、1つの目標あたりの件数が月に数件しかなければ、学習が進みません。
考え方はシンプルです。コンバージョンのパターンが違うなら分ける。ただし、1つの目標に十分なデータ量がなければ、一段まとめる。データが蓄積されてきたら改めて分ける。データ量と粒度のバランスです。
コンバージョン設定とは、単に「何を計測するか」ではありません。機械学習に「何を正解として学習してほしいか」を教えることです。何を正解にするか、件数で数えるか金額で重みをつけるか、どの粒度で分けるか。これらはすべて、機械学習の学習方向を決める判断です。正解データが汚れていれば、天気予測で間違った気温を教えているのと同じ。どれだけデータを増やしても、手がかりを増やしても、正解がおかしければ予測は当たりません。
なお、オフラインのコンバージョン(電話での成約、店舗での契約など)をGoogle広告に教える場合は、GCLID(Google Click Identifier)という識別子で広告クリックとコンバージョンを紐づけます。GCLIDは正解データそのものではなく、「このクリックがこのコンバージョンにつながった」と紐づけるためのキーです。
天気予報の予測コードで体験する
ここまで読めば広告の「学習」の仕組みは理解できているはずです。このセクションは、「実際に機械学習のコードを動かしてみたい」という人向けの補足です。読み飛ばしても問題ありません。
記事で説明した天気予測を、実際にコードで動かします。Open-Meteoという無料の天気APIから東京の過去90日分の気象データを取得し、翌日の最高気温を予測するPythonスクリプトのハイライト部分を載せます。
# 手がかりと正解の準備
# 過去の気象データから「予測の手がかり」を作る
features = df[["temperature", "humidity", "pressure", "wind_speed"]]
# 「正解」= 翌日の最高気温
labels = df["next_day_max_temp"]
# 学習用データとテスト用データに分割
X_train, X_test, y_train, y_test = train_test_split(
features, labels, test_size=0.2
)
# モデルを作って学習させる
model = RandomForestRegressor()
model.fit(X_train, y_train) # ← ここが「学習」
# 新しいデータで予測する
prediction = model.predict(X_test) # ← ここが「推論」model.fit() が「学習」、model.predict() が「推論」です。Google広告の管理画面で「学習中」と表示されている間、裏側ではこれと同じ構造の処理が走っています。規模とアルゴリズムの複雑さは桁違いですが、やっていることの骨格は同じです。
全体のコード(APIからのデータ取得・前処理・予測精度の評価まで含む)は、GitHubリポジトリで公開しています。uvがあれば uv run predict_temperature.py だけで動きます。
まとめ
広告の「学習」は、ブラックボックスでもマーケティング用語でもありません。過去のデータからパターンを見つけて未来を予測する、機械学習そのものです。
その仕組みがわかると、管理画面の設定の一つ一つに意味が見えてきます。
- ▶ コンバージョン設定は、機械学習に「何を正解として学習してほしいか」を教えること
- ▶ 学習期間は、十分なデータを集めてパターンを見つけるのに必要な時間
- ▶ シグナルは、予測の精度を上げるための手がかり
仕組みを知っていれば、「なんとなく待つ」から「根拠を持って判断する」に変わります。