
PostgreSQL 18は速いのか、17から2000万件で実測【2026年版】
PostgreSQL 18は本当に速いのか。17.9と18に同じ2000万件を入れて実測したら、目玉の非同期I/Oが効くはずの大きな集計はむしろ遅くなりました。はっきり速くなったのは複合索引の絞り込みだけ。設定ひとつで結果がひっくり返る場所もあります。上げる前に知るべき実データを示します。
目次
PostgreSQL 18は本当に速いのか。17.9と18に同じ2000万件を入れて実測したら、目玉の非同期I/Oが効くはずの大きな集計はむしろ遅くなりました。はっきり速くなったのは複合索引の絞り込みだけ。設定ひとつで結果がひっくり返る場所もあります。上げる前に知るべき実データを示します。
「18にすれば全部速くなる」は、実測すると違った
このブログ自身を PostgreSQL 17.9 から 18 に上げる前に、「実際どれくらい変わるのか」を手元で測りました。17.9 と 18 のコンテナを2つ立て、まったく同じ2000万件のデータを入れて、業務でよくある5種類のテーブルとクエリで比べています。
結果は予想と違いました。PostgreSQL 18の目玉とされる「非同期I/O」が効くはずの大きな集計クエリは、むしろ17より遅くなりました。はっきり速くなったのは1か所(スキップスキャン)だけ。残りは「変わらない」か「設定次第」です。誇張なしの実測値を、まず一覧で出します。
| あなたのテーブル | PostgreSQL 17.9 | PostgreSQL 18 | どうなったか |
|---|---|---|---|
| 業務テーブルの絞り込み (スキップスキャン) | 847ms | 585ms | 速くなった |
| 売上・ログの集計レポート (非同期I/O) | 4.3秒 | 7.1秒 | 逆に遅くなった |
| 多テーブルをたどるJOIN集計 | 1.7秒 | 2.3秒 → 1.1秒 | 設定次第 |
| ログイン(メールで1人検索) | 1ms未満 | 1ms未満 | 変わらない |
| 記事のあいまい検索(部分一致) | 8.2ms | 8.1ms | 変わらない |
「JOINの 2.3秒 → 1.1秒」は、18の非同期I/Oの設定(io_method)を既定値から変えたときの差です。ここがこの記事のいちばん大事なポイントなので、後で詳しく書きます。
使った検証コードは全部 GitHub に置いてあります。docker compose とコマンド数本で、誰でも同じ比較を再現・追試できます(リンクは末尾)。数値はあくまで「ある1つの環境での実測」です。鵜呑みにせず、自分の環境で確かめてほしいので公開しています。
なぜ測ったのか
PostgreSQL 18は2025年9月にリリースされた、データベース管理システムの最新メジャーバージョンです。目玉として「非同期I/O」「スキップスキャン」「アップグレード時の統計情報引き継ぎ」などが入り、リリースノートには「速くなる」と書いてあります。
ただ、リリースノートの「速くなる」は条件付きです。どんなテーブルで、どんなクエリで、どれくらい変わるのか。ここがわからないと、本番を止めてまでアップグレードする判断ができません。ちょうどこのブログのデータベースを 17.9 から上げる計画があったので、上げる前に自分のユースケースに近い形で測ることにしました。
以前、主キーをUUIDにすべきかbigintにすべきかを1000万件で検証した記事でも PostgreSQL 18 を使いました。今回はその続きで、「バージョンを上げること自体」で何がどう変わるのかを正面から見ます。
どう測ったか
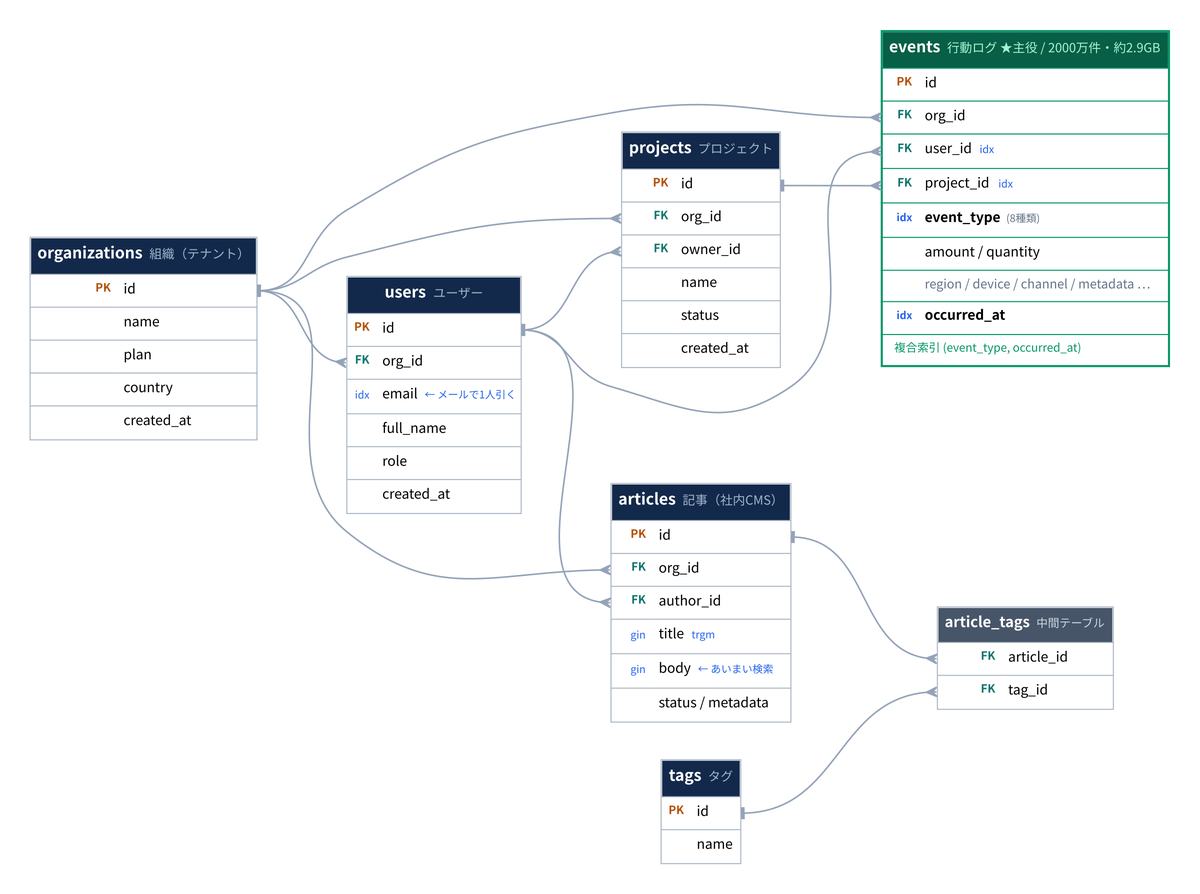
業務SaaS(プロジェクト管理+行動ログ分析+社内の記事管理)を題材に、実務でありがちな7つのテーブルを1つのデータベースにまとめました。組織・ユーザー・プロジェクト・行動ログ・記事などです。読者が「自分のところもこんなテーブルだ」と当てはめられることを重視しています。
データは「種プール増幅」でリアルさと量を両立
中身が空っぽのダミーデータでは、現実の検索の重さは測れません。かといって、Faker(実在感のある氏名・会社名・文章を生成するライブラリ)で2000万件を1件ずつ作ると日が暮れます。
そこで、Faker でリアルな「種プール」(氏名・会社名・文章を数万件)を一度だけ作り、それを組み合わせて大量行へ COPY で増幅しました。実在感を保ったまま量を稼ぐやり方です。乱数の種を固定しているので、17.9 と 18 にはまったく同じデータが入ります。これでバージョンの差だけを取り出せます。
# Fakerで一度だけ種プールを生成(数万件)→ あとは組み合わせてCOPYで増幅 names = [fake.name() for _ in range(50000)] # 実在感のある氏名 sentences = [fake.text() for _ in range(5000)] # 記事本文の素材 # 行動ログ2000万件は、この種プールを samples して COPY で流し込む
shared_buffers(PostgreSQLが自分用に確保するメモリ)は256MBに絞り、ディスクからの読み込みが起きる状態にしました。行動ログテーブルは2000万件で約2.9GB。各クエリを EXPLAIN (ANALYZE, BUFFERS) で5回流して中央値を取り、環境は Docker 上の PostgreSQL 17.9 と 18、8コア・メモリ7.6GBのマシンです。「40%速い」のような割合ではなく、人間が画面の前で実際に待つ秒数で見ていきます。
いちばん意外だった:大きな集計が18で「遅く」なった
売上やアクセスログを月別・地域別に集計するダッシュボード系のクエリです。インデックスを使わずテーブル全体を読んで集計するタイプで、PostgreSQL 18の目玉「非同期I/O」がいちばん効くと期待していた場所でした。
非同期I/Oとは、ざっくり言うと「ディスクに何件もまとめて読み取りを依頼し、待っている間に次の処理を進める」仕組みです。PostgreSQL 18では io_method という設定が入り、既定で worker(専用プロセスがまとめて先読みする方式)になっています。
ところが結果は逆でした。同じ集計が、17.9で4.3秒、18(既定)で7.1秒。18のほうが1.6倍遅い。5回測っても安定して遅く、誤差ではありませんでした。
原因は非同期I/Oの方式だろうと当たりをつけ、io_method を切り替えて測り直しました。
| 大規模集計(2000万件) | 実行時間 |
|---|---|
| PostgreSQL 17.9 | 4.3秒 |
| PostgreSQL 18(io_method=worker・既定) | 7.1秒 |
| PostgreSQL 18(io_method=sync) | 6.2秒 |
| PostgreSQL 18(io_method=io_uring) | 6.1秒 |
io_method を io_uring に変えると7.1秒→6.1秒まで縮みましたが、それでも17.9の4.3秒には届きません。この集計クエリに関しては、今回の環境では18に上げると遅くなる、という結果です。
大事な注意を書いておきます。非同期I/Oの効果はストレージの種類に強く左右されます。今回は普通のクラウドのディスクで測りました。ローカルの高速NVMe SSDや、きちんとチューニングした環境では結果が変わる可能性は十分あります。それでも、「18にすればI/Oが速くなって集計も速くなる」と無条件に信じるのは危険だ、というのが実測から言えることです。大きな集計を多用しているなら、上げる前に必ず自分の環境で測ってください。
はっきり速くなったのはここ:業務テーブルの絞り込み

5つのうち、18でちゃんと速くなったのがこれです。マルチテナント(複数の会社が1つのシステムを共有する)SaaSでよくある、行動ログテーブルを期間で絞り込むクエリです。
このテーブルには「種類(閲覧・クリックなど8種類)と日時」をセットにした複合インデックス(索引)を張っています。実務でありがちな構成です。ところが、クエリが「日時だけ」で絞ると、PostgreSQL 17 はこの索引をうまく使えません。先頭の「種類」が指定されていないからです。結果、テーブル全体を頭から舐める シーケンシャルスキャン(全表走査) に倒れます。
PostgreSQL 18のスキップスキャンは、ここで「種類」の8種類を内部で読み飛ばしながら、日時の索引だけを使えるようになりました。同じSQL・同じデータ・同じインデックスなのに、実行計画が別物に切り替わります。実測では 847ms → 585ms。読み取ったディスクブロックも、17の約37万から18は約15万へ大きく減っていました。
-- PostgreSQL 17.9(複合索引の先頭列が無いので全表走査に倒れる) Parallel Seq Scan on events -- 約37万ブロック読む -- PostgreSQL 18(スキップスキャンで索引を使う) Bitmap Index Scan on idx_events_type_time -- 約15万ブロックで済む Index Searches: 17 -- 索引を何回かに分けて探索(これがスキップスキャン)
ここで大事なのは、これが「インデックスを張り直さなくても効く」点です。アプリのコードも、テーブル定義も、インデックスもそのまま。バージョンを上げるだけで、これまで全表走査だったクエリが索引を使うようになります。多くの会社が持っている「とりあえず複合インデックスを張った業務テーブル」が、いちばん恩恵を受けます。
速くなる幅は、絞り込んだ結果が少ないほど大きくなります。同じクエリを1000万件・もっと狭い期間で試したときは 34ms → 5.6ms(約6倍) と劇的でした。今回の2000万件では結果が約19万件と多く、その分だけ差は縮みます(それでも索引が効くぶん速い)。「自分の検索が何件返すか」「複合索引の先頭列が何種類あるか」で効き目が変わります。先頭列が何百万種類もあると、読み飛ばす回数が増えて旨味は減ります。
深いJOINは「既定だと遅い、設定を変えると速い」
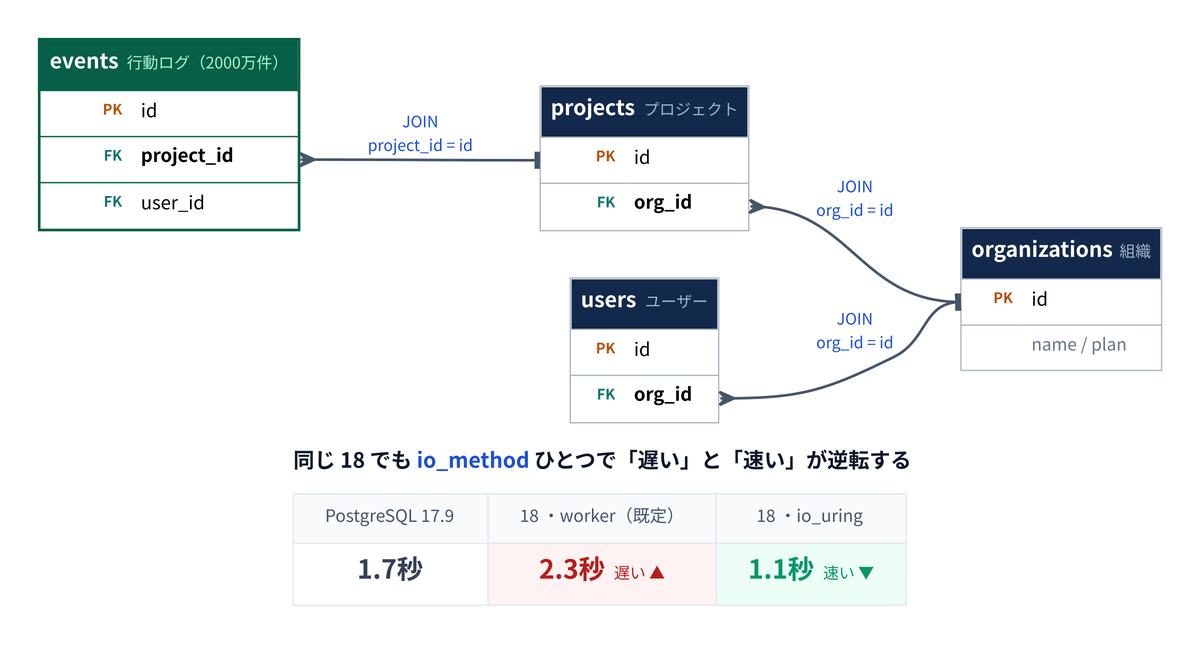
行動ログ→プロジェクト→組織→ユーザーと4つのテーブルをたどる、深いJOIN集計も測りました。ここがいちばん「設定次第」がはっきり出た場所です。
| 深いJOIN集計(2000万件) | 実行時間 |
|---|---|
| PostgreSQL 17.9 | 1.7秒 |
| PostgreSQL 18(worker・既定) | 2.3秒(17より遅い) |
| PostgreSQL 18(io_uring) | 1.1秒(17より速い) |
既定の worker では17より遅い(1.7秒→2.3秒)のに、io_method=io_uring に変えると17より速くなりました(1.1秒)。同じ18でも、I/Oの方式ひとつで「遅い」と「速い」がひっくり返ります。
ここから言えるのは1つ。PostgreSQL 18に上げたら、まず io_method を自分のワークロードで比べるべきだということです。既定の worker が常に最適とは限りません。Linuxで新しめのカーネルなら io_uring を試す価値があります。
認証とあいまい検索は、まったく変わらなかった
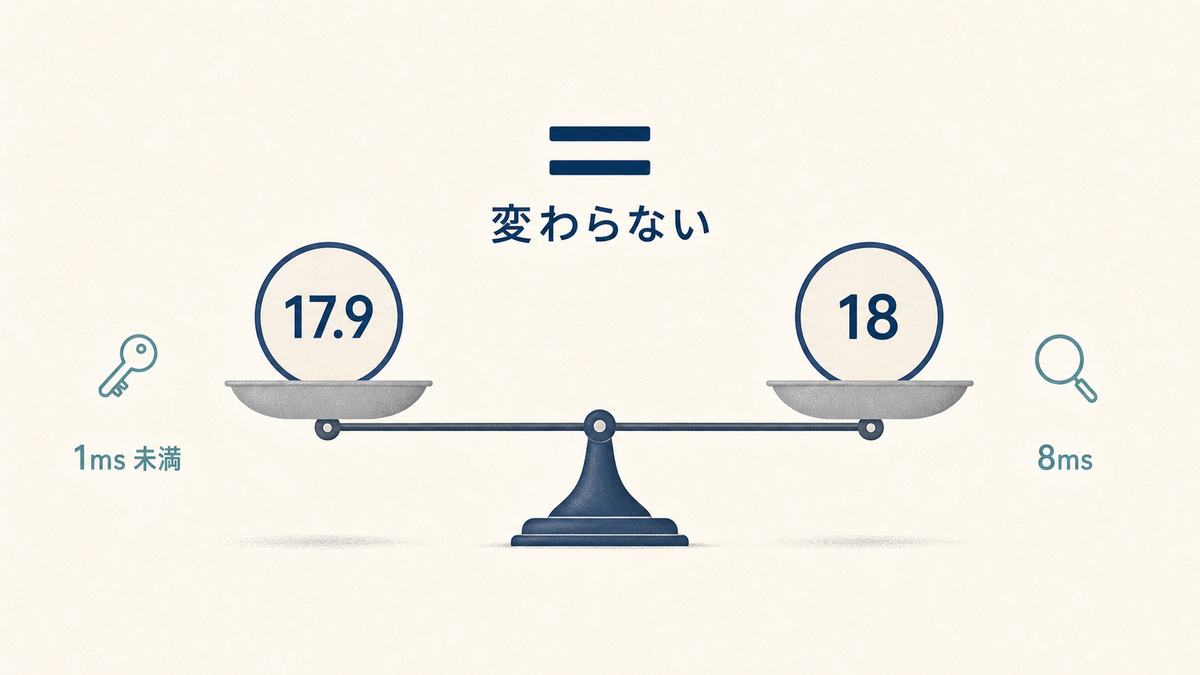
ログイン時の「メールアドレスで1人を引く」点ルックアップは、17も18も1ミリ秒未満で一瞬。元々インデックスで一瞬なので、ここはアップグレードしても体感は変わりません。記事のあいまい検索(部分一致)も 8.2ms → 8.1ms と、ほぼ同じでした。
これは悪い知らせではありません。「認証やマスタ参照のような軽いクエリ中心のシステムは、18に上げても速度面の体感は変わらない」とわかること自体が、アップグレード判断の材料になります。速くなる/遅くなるの変化が出るのは、大きなテーブルをまとめて読むような重いクエリだけです。
アップグレード当日の落とし穴:統計情報の引き継ぎ

速度の良し悪しとは別に、運用で地味に効くのが「統計情報の引き継ぎ」です。これは知らないとアップグレード当日にハマります。
PostgreSQLは「どのデータがどれくらいの量・分布で入っているか」という統計情報をもとに、最適な実行計画を立てます。ところが PostgreSQL 17 までは、pg_upgrade(バージョン間移行ツール)でアップグレードするとこの統計情報が引き継がれませんでした。移行直後はデータベースが「中身を何も知らない」状態になり、ANALYZE という統計の取り直しを手動で走らせるまで、誤った実行計画で遅くなります。
この ANALYZE はテーブルが大きいほど時間がかかります。今回の2000万件では約1秒で済みましたが、数千万〜億行規模になると数分かかることもあります。その間、本番が本調子に戻りません。PostgreSQL 18は pg_upgrade が統計情報を引き継ぐようになり、移行が終わった瞬間から最初のクエリが正しい計画で動きます。アップグレード直後の「なぜか全部遅い」時間がゼロになります。地味ですが、ダウンタイムを短くしたい本番運用では大きい改善です(拡張統計だけは引き継がれない、--no-statistics で無効化できる、といった細かい注意はあります)。
セキュリティと、廃止・非推奨になったもの
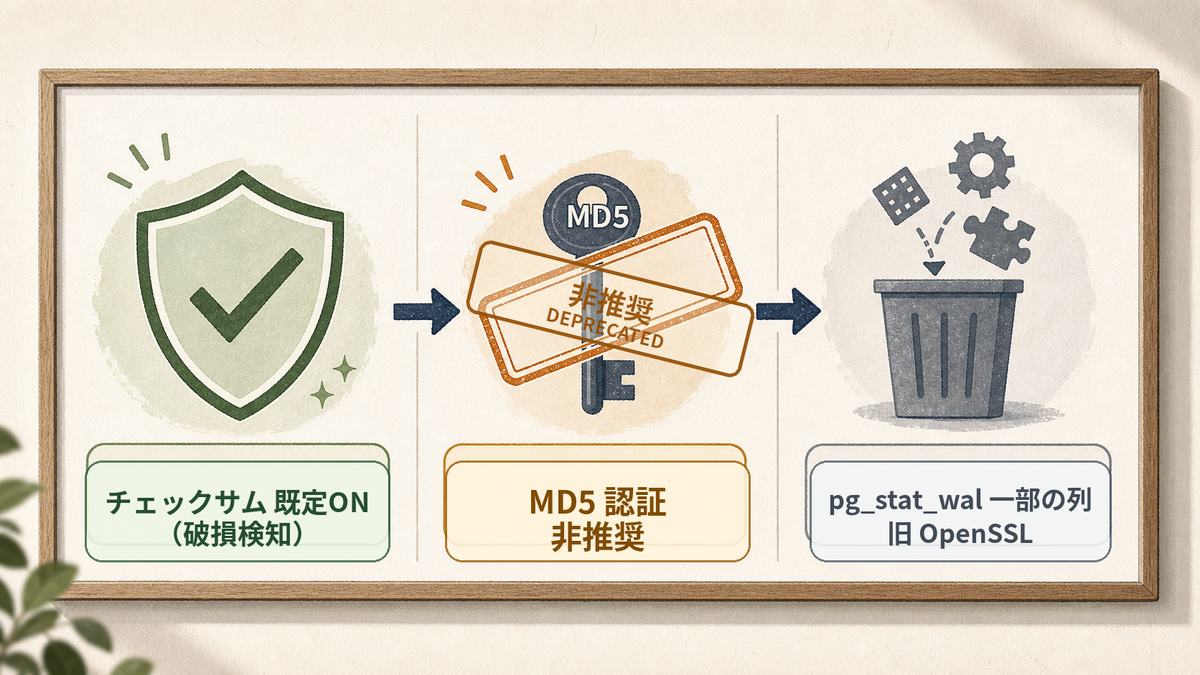
速度以外で、上げる前に知っておくべき変更もあります。実際に17.9と18のコンテナで挙動を確認しました。
データの破損検知が既定でオンに
PostgreSQL 18では、新しくデータベースを初期化するとデータチェックサム(保存データの破損を検知する仕組み)が既定で有効になりました。実際に確認すると、17.9は data_checksums = off、18は on です。安全側に倒れた良い変更ですが、注意点があります。pg_upgrade は移行元と移行先でチェックサム設定が一致している必要があるため、チェックサム無しの古いクラスタから上げるときは、移行先を --no-data-checksums で初期化するなどの調整が要ります。
古いパスワード方式(MD5)が非推奨に
古い認証方式である MD5 パスワードが正式に非推奨になりました。18でMD5パスワードのユーザーを作ろうとすると、はっきり警告が出ます(17では何も出ません)。
-- PostgreSQL 18 で MD5 パスワードを設定すると…
WARNING: setting an MD5-encrypted password
DETAIL: MD5 password support is deprecated and will be removed
in a future release of PostgreSQL.将来のバージョンで完全に削除される予定です。MD5を使っているなら、より安全な scram-sha-256 方式への移行を今のうちに進めておくべきです。
削除されたもの(上げる前に要確認)
PostgreSQL 18 で完全に削除された主なものは次の通りです。古い環境から上げる場合は、これらに依存していないか先に確認してください。
- •
pg_stat_walの一部の列(wal_write/wal_syncなど)。監視ツールが参照していると壊れる可能性があります - •OpenSSL 1.1.1 より古いバージョンのサポート
- •ビルド時オプション
--disable-spinlocks/--disable-atomics、および古いCPUアーキテクチャ(HP-PA)
なお、前回の主キー検証でも触れた uuidv7()(時系列順に並ぶID生成関数)も18の正式機能です。あわせて、生成列(計算で値が決まる列)の既定が「保存せず読むたび計算する」方式(VIRTUAL)に変わった点も、テーブル定義を移すときの確認ポイントです。
この検証の限界
フェアに書いておきます。以下は今回測れていません。
- ?ストレージごとの差。非同期I/Oの効果はディスクの速さ・種類に強く依存します。今回の「18で集計が遅い」も、別のストレージでは結果が変わる可能性があります
- ?もっと大きな規模。今回は検証マシンの都合で2000万件を上限にしました(リポジトリのコードは
SCALEを変えれば5000万・1億件も流せます) - ?書き込み(INSERT/UPDATE)中心の負荷。今回は読み取り系のクエリに絞っています
数値そのものより、「どの種類のテーブル・クエリで変わり、どこは変わらないか」「設定でひっくり返る場所がある」という地図として読んでもらえればと思います。条件を変えた追試は、後述のリポジトリでそのままできます。
まとめ:上げる価値はあるか
「全部が速くなる」わけではありませんでした。むしろ、目玉の非同期I/Oが効くと思っていた大きな集計は、今回の環境では逆に遅くなりました。それでも、結論は「上げる価値はある」です。理由は3つです。
① 複合インデックスを張った業務テーブルがあるなら、スキップスキャンだけで価値がある。コードもインデックスもそのままで、全表走査だったクエリが索引を使うようになります。② 統計情報の引き継ぎ・チェックサム既定オン・MD5非推奨など、運用とセキュリティの改善がまとまって入っている。これは計画的に上げる十分な理由になります。
③ ただし、上げたら必ず自分の環境で測ること。とくに大きな集計やJOINを多用しているなら、io_method を worker / sync / io_uring で比べてください。既定値が最適とは限らず、ここを変えるだけで「遅い」が「速い」に変わることがあります。
このブログのデータベースも、この結果を踏まえて 18 へ上げることにしました(io_method は実環境で比較してから決めます)。次は書き込み負荷でも測ってみたいと思っています。
参照元・検証コード
- •検証コード一式(GitHub) — docker-compose・データ生成・ベンチ・グラフ。
make数本で再現できます - •PostgreSQL 18 リリースノート(公式)
- •UUIDv4 vs v7 vs bigint、PostgreSQLで1000万件検証(関連記事)
- •計測手法:
EXPLAIN (ANALYZE, BUFFERS)5回の中央値、PostgreSQL 17.9 / 18、同一データ(乱数固定)、shared_buffers=256MB、メモリ7.6GB・8コア
堀川 慎
Backend Engineer / AWS / Django / Go